Навярно повечето от вас знаят, че се занимавам със сайта fuelo.net и на мен се стоварват всички технически проблеми. В този пост искам да споделя два от основните проблемите пред подобен род приложения – силно зависими от местоположението на потребителите, и как съм ги разрешил.
1. Намиране на най-близките N обекта (в нашия случай бензиностанции).
Във fuelo използваме MySQL за основен database и една от първите ми оптимизации беше да upgrade-нем до версия 5.7, където има доста подобрения и готови функции, свързани с геолокацията. Първоначално всички заявки свързани с определяне на бензиностанции наблизо бяха нещо от рода на :
$sql = "SELECT *, (6371 * acos( cos( radians(".$lat.") ) * cos( radians(`lat`) ) * cos( radians(`lon`) - radians(".$lon.") ) + sin( radians(".$lat.") ) * sin( radians(`lat`) ) ) ) AS `distance` FROM `gasstations` HAVING `distance` < ".$distance." ORDER BY `distance` ASC";
забележка: всички примери ще бъдат на PHP, а заявките са опростени (без WHERE и LIMIT клаузи) с цел прегледност.
Както виждате тук дори не се използва stored procedure, а цялата haversine формула се изчислява при всяка заявка. Това при малък ненатоварен сайт с неголяма база данни (напр. до 1000 обекта) на практика работи и се използва доста често. Повечето tutorials в интернет препоръчват именно тази формула. Първата ми идея за MySQL 5.7 беше именно да заменим тази формула с вградената (от версия 5.7.6) функция ST_Distance_Sphere. Така горната заявка се свива до:
$sql = "SELECT *, ST_Distance_Sphere(POINT(`lon`, `lat`), POINT(".$lon.", ".$lat."), 6371) AS `distance` FROM `gasstations` HAVING `distance` < ".$distance." ORDER BY `distance` ASC";
Така изчислението на теория (и на практика) става много по-бързо. Забележете, добавения трети параметър на функцията ST_Distance_Sphere, който преобразува изчислението в km, а не в метри както е по подразбиране. Това ни се наложи, за да запазим съвместимостта със функциите, които извикваха тази заявка, а те очакват резултата в километри.
На пръв поглед всичко изглежда супер, но на практика не е. Тази функция наистина изчислява възможно най-бързо разстоянието между две точки, но не използва индекси и затова все пак трябва да обходи всички редове в таблицата, за да подреди резултатите по разстояние. При все по-голяма база (при нас като наближихме 50000 бензиностанции), тази заявка също започна да става бавна. Започнах да мисля как да огранича резултатите, за които се изчислява разстоянието. Както се вижда от заявките (почти) винаги има ограничение в разстоянието (HAVING `distance` < X) и се зачудих как мога да превърна това X в координати и така да огранича резултатите още преди да започне изчислението и сортирането. Така намерих тази статия (Finding Points Within a Distance of a Latitude/Longitude Using Bounding Coordinates by Jan Philip Matuschek), в която на теория много добре е описан точно моя проблем. Има и source код на Java, както и линкове за други програмни езици, включително и PHP. Това беше точно каквото ми трябваше. Като използвам тази библиотека кода придобива следния вид:
$edison = Geolocation::fromDegrees($lat, $lon);
$coordinates = $edison->boundingCoordinates($distance, 'km');
$lat_min = $coordinates[0]->getLatitudeInDegrees();
$lon_min = $coordinates[0]->getLongitudeInDegrees();
$lat_max = $coordinates[1]->getLatitudeInDegrees();
$lon_max = $coordinates[1]->getLongitudeInDegrees();
$sql = "SELECT *, ST_Distance_Sphere(POINT(`lon`, `lat`), POINT(".$lon.", ".$lat."), 6371) AS `distance` FROM `gasstations` WHERE `lat` > '".$lat_min."' AND `lat` < '".$lat_max."' AND `lon` > '".$lon_min."' AND `lon` < '".$lon_max."' HAVING `distance` < ".$distance." ORDER BY `distance` ASC";
Така вече заявката беше доста по-бърза, обхождаше доста по-малко редове, което подобри работата на MySQL и сървъра като цяло. Аз обаче не се спрях до тук. Хрумна ми как да се възползвам от spatial индекса на MySQL. Първо направих ново поле в таблицата gasstations с име coords и тип POINT. Попълних новото поле от другите две полета, които вече имах, lat и lon , чрез заявката UPDATE `gasstations` SET coords = Point(lon, lat); и след това направих полето spatial index. След тази промяна бях готов за последната ми (за сега) SQL заявка за намиране на най-близките бензиностанции:
$edison = Geolocation::fromDegrees($lat, $lon);
$coordinates = $edison->boundingCoordinates($distance, 'km');
$lat_min = $coordinates[0]->getLatitudeInDegrees();
$lon_min = $coordinates[0]->getLongitudeInDegrees();
$lat_max = $coordinates[1]->getLatitudeInDegrees();
$lon_max = $coordinates[1]->getLongitudeInDegrees();
$sql = "SELECT *, ST_Distance_Sphere(`coords`, POINT(".$lon.", ".$lat."), 6371) AS `distance` FROM `gasstations` WHERE ST_Within(`coords`, ST_MakeEnvelope(Point(".$lon_min.", ".$lat_min."), Point(".$lon_max.", ".$lat_max."))) HAVING `distance` < ".$distance." ORDER BY `distance` ASC;
Същността тук е функцията ST_Within(), която се възползва от spatial index-а на coords и филтрира резултатите още по-бързо. Функцията ST_MakeEnvelope създава “квадрат”, по две крайни точки, в който се ограничава търсенето.
За сега това ми е решението за намиране на най-близките бензиностанции. Не мога да дам сравнителни стойности, защото междувременно условията много се променяха, но на практика нещата вървят много по-добре. Бавните заявки намаляха и натоварването на сървъра спадна.
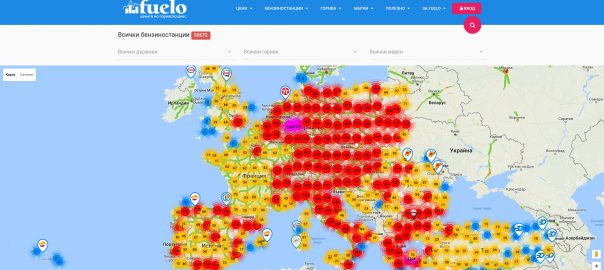
2. Изобразяване на голям брой обекти на карта
Във fuelo използваме Google Maps за визуално представяне на бензиностанциите на карта. В началото беше лесно – малко обекти – просто показвай всички на картата. След време, както всички, започнахме да използваме js marker clusterer. Така обаче прехвърляме тежките изчисления върху клиента и когато той реши да unzoom-не за да види всички бензиностанции в Европа, може направо да му забие browser-а и/или компютъра. Започнах да търся сървърно решение за clustering на обекти. Решението, което използваме в момента, се нарича geohash. MySQL поддържа geohash функции и с тяхна помощ заявката за server-side clustering става нещо подобно:
$sql = "SELECT `id`, `brand_id`, AVG(lat) as avglat, AVG(lon) as avglon, substring(`geohash`, 1, ".$precise.") as cluster_hash, count(*) as cluster_count
FROM `gasstations`
WHERE ST_Within(`coords`, ST_MakeEnvelope(Point('.$lon_min.', '.$lat_min.'), Point('.$lon_max.', '.$lat_max.')))
GROUP BY `cluster_hash`";
За целта Ви трябват няколко неща:
- поле geohash (при мен VARCHAR(9) ) в таблицата gasstations, което предварително е попълнено със ST_GeoHash() функцията (и не забравяйте да го update-вате винаги, когато промените координатите на обекта ! )
- $lon_min, $lat_min, $lon_max и $lat_max , които лесно може да вземете за видимата част на картата от google maps API-то
- $precise – колко прецизно да е клъстерирането. Основно зависи от zoom level-а на картата и може да си го нагласите според вашите нужди
При изпълнение на заявката получавате всичко необходимо за визуализиране на картата и не е необходимо на използвате client-side clustering:
- cluster_count е броя обекти в клъстера – ако е 1, значи е само една бензиностанция и може да покажете пинче в зависимост от нейната brand_id. Ако е повече от 1 значи има повече от една бензиностанция в района и показвате клъстерна иконка с цифричка cluster_count, която показва броя.
- avglat и avglon са средноаритметично от координатите на бензиностанциите и така може да позиционирате клъстерната иконка на “по-правилно” място. Иначе, от самата специфика на geohash алгоритъма, Земята се разделя на правоъгълници и клъстерите Ви ще се наредят като в решетка. Разбира се ако cluster_count e 1, avglat и avglon са координатите на самата бензиностанция.
Това са решенията и заключенията до които стигнах за тези два проблема и ще се радвам, ако съм полезен на някой.